Looking for the next big scaling lever for robotics? Language may be the fastest one. 🚀
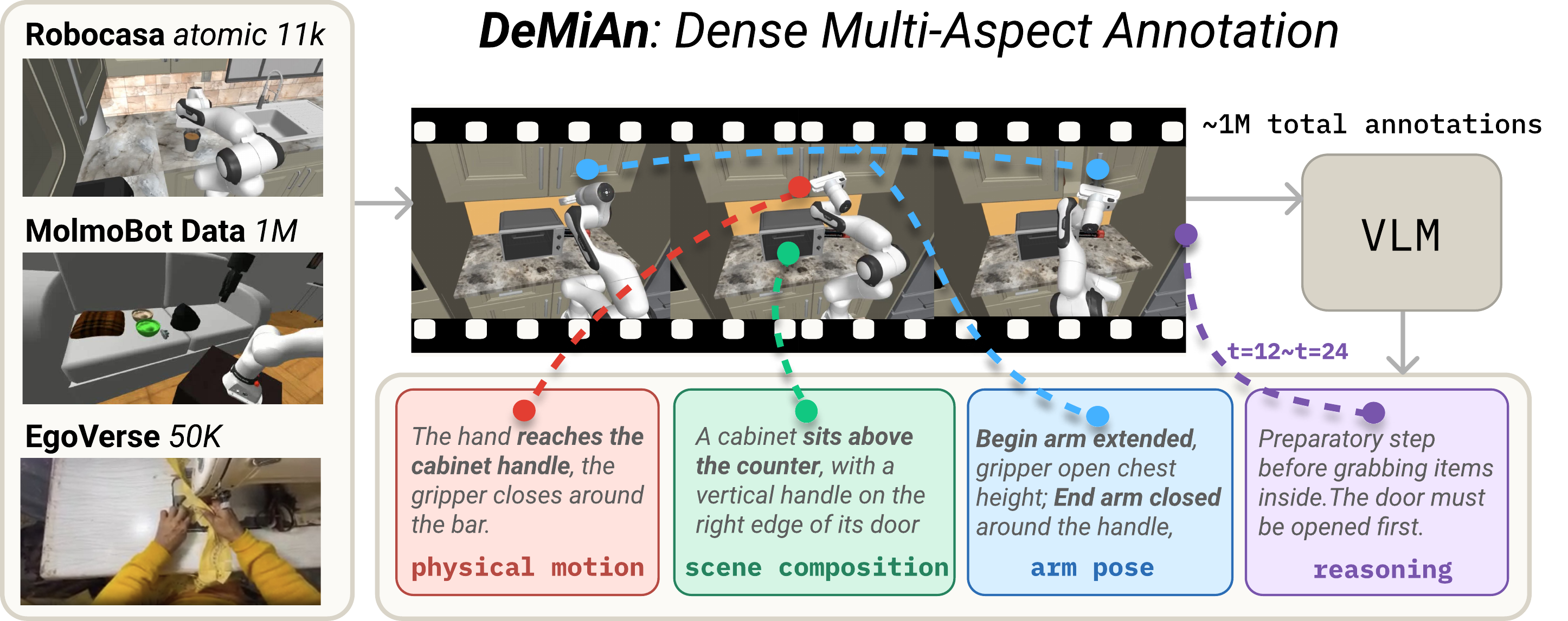
Teaching robots new skills usually means recording thousands of hours of expensive human-driven robot demos. Each demo is paired with a tiny one-line label like “open the drawer” — which throws away most of the useful information already present in the video. We introduce DeMiAn (Dense Multi-Aspect Annotation), which keeps the same videos and just rewrites the labels: a vision-language model produces richer descriptions per clip, and a small instructor model learns to hand the robot the right kind of description, in real time. With DeMiAn, we achieve +5 points success rate on RoboCasa365 and ~62% compute savings on MolmoSpaces — with zero new demonstrations collected.
Core contributions
- A new scaling axis for robot learning. DeMiAn opens one more scaling axis — language density — that simply stacks on top of video demonstrations. Applied to 1M+ robot clips and 50K human-egocentric clips for an average +5 point lift (up to +37 on a single task), with no additional demonstrations.
- A smart instructor and real-time deployment. No single style of description works best everywhere, so we train a small instructor model that watches the initial scene and writes the tailored description for each task on the fly. It runs in parallel with the robot, so the robot never waits.
- Better generalization to harder, unseen tasks. Our policies generalize better to longer multi-step (composite) tasks and to scenes and objects never seen during training; +9 points on unseen composite tasks.
- A more compute-efficient lever for scaling. Re-labeling existing videos improves the compute–performance frontier of robot learning, even after charging annotation compute into the budget. At 1M-clip scale, DeMiAn matches the no-annotation baseline with ~62% less compute (~1.3 × 10²⁰ FLOPs saved).
A new scaling axis for robotics
Results on RoboCasa365 and MolmoSpaces
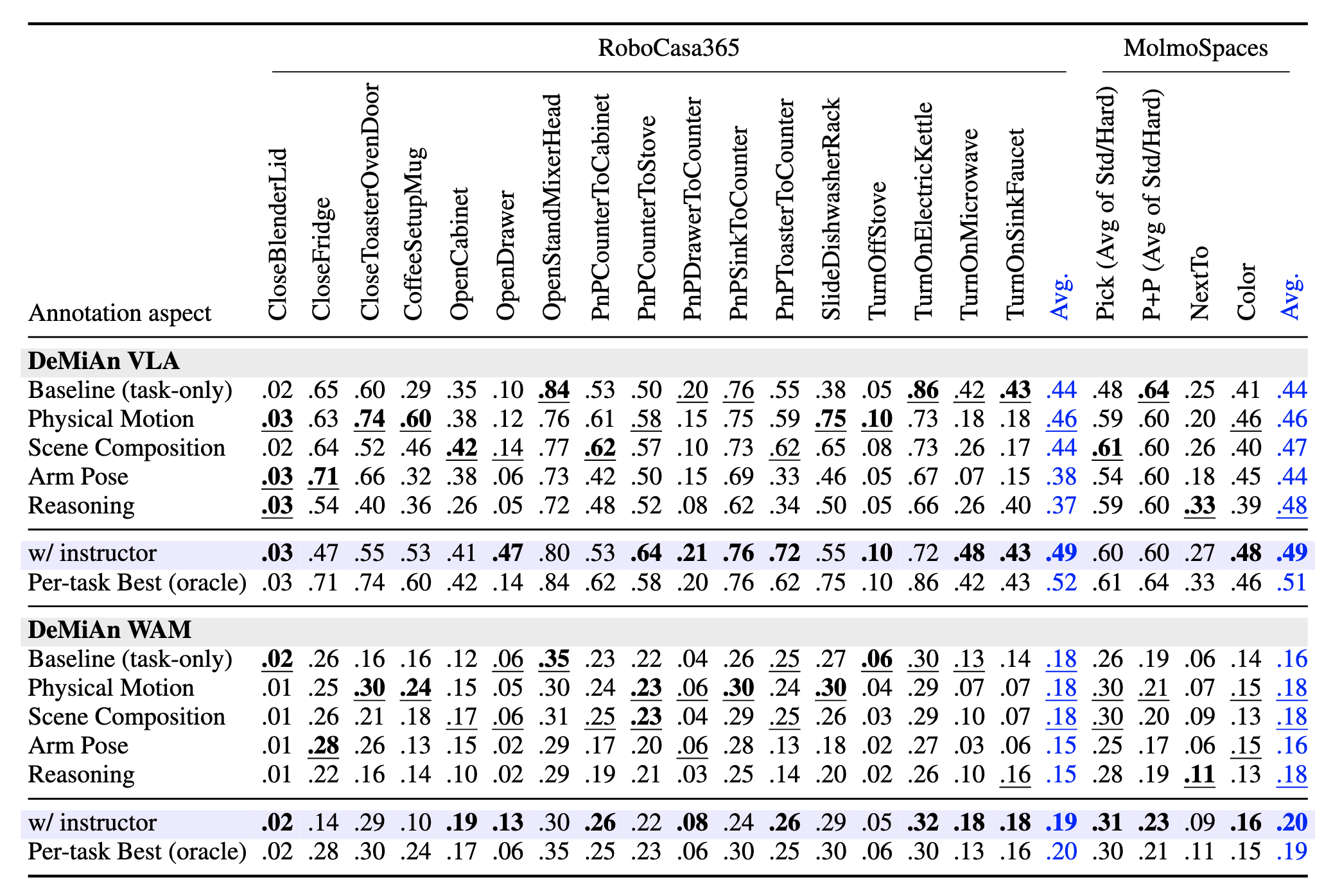
We found that no fixed annotation rule reaches the per-task oracle. The optimal aspect varies with the structural demands of each task family — contact-changing motion vs. open-vocabulary grounding. Closing this gap requires producing the right instruction for each task at deployment.
A smart instructor and real-time deployment
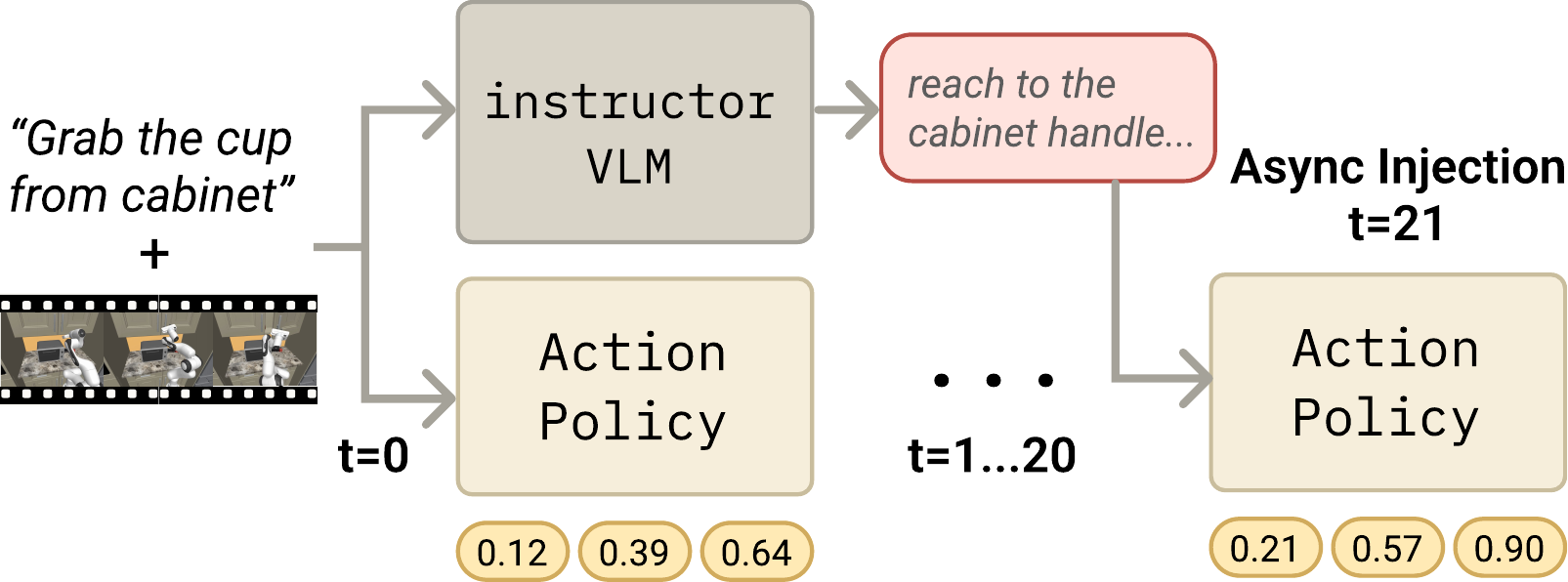

We close the oracle gap with a small learned instructor model: given the same observation the action policy receives, it generates a scene-grounded annotation.
Instructor closes the oracle gap. The instructor lifts average SR from 44% → 49% on RoboCasa and MolmoSpaces, within 2–3 points of the per-task oracle (51–52%). Against a random per-episode aspect baseline (46.6%) with the same action policy checkpoint, the instructor adds +3.8 points — the gain comes from learned per-task selection, not heuristic routing.
Async deployment, zero policy delay. At test time the instructor decodes asynchronously while actions emit at the action server’s native 8-step open-loop cadence. Until the instruction is ready, the policy executes on the task description alone — equivalent to the no-annotation baseline. The moment the instruction completes, it is spliced into the reasoning field at the next chunk boundary, and subsequent action chunks condition on it.
Generalizing to harder, unseen tasks



Our policy models are trained on RoboCasa365 atomic tasks. We test generalization to new instruction formats on composite tasks under two prompting strategies: -fix feeds a single composite task description for the whole episode; -dynamic runs a subgoal-driven state machine that swaps the prompt to the in-distribution atomic instruction for the current phase once a lenient in-simulator trigger fires.
Within the OOD -fix format, DeMiAn-VLA improves over the task-only baseline by +2 full-task points (15% vs. 13%). With GT atomic prompts under -dynamic, DeMiAn-VLA-GT is the strongest configuration overall (22% vs. 19% baseline-GT) — the dense-annotation policy benefits more from subgoal-decomposed prompts than the baseline does.
A compute-efficient lever for scaling
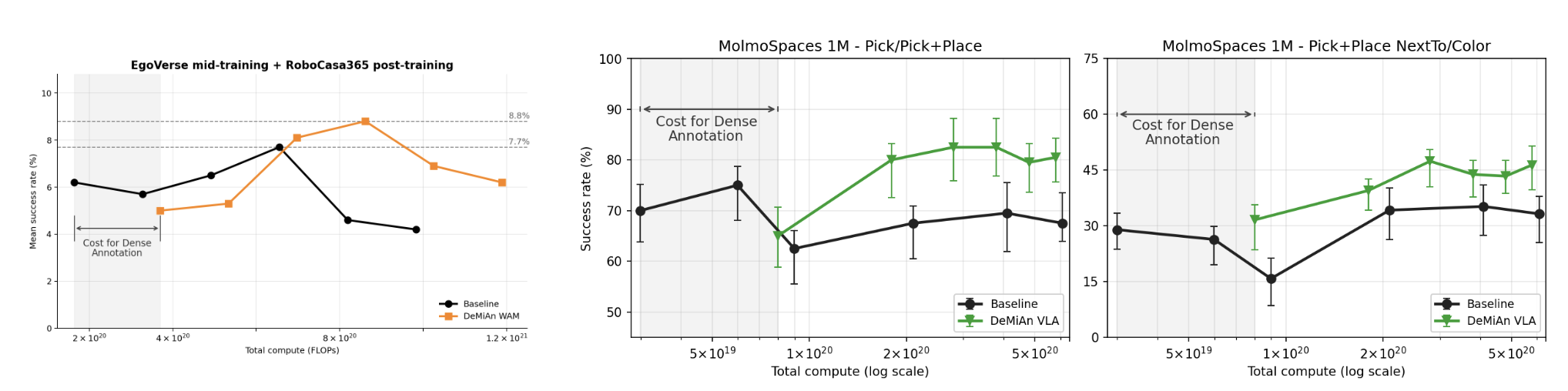
Scaling under matched compute. We mid-train Cosmos-Predict 2.5 on 50K EgoVerse clips with and without dense annotations, and post-train DeMiAn-WAM on RoboCasa365 under both conditions. After the small upfront cost of generating annotations, the annotated WAM reaches higher downstream RoboCasa SR than the baseline at nearby compute budgets. On MolmoBot post-training with 1M trajectories, annotation-conditioned policies reach stronger MolmoSpaces SR earlier in training and obtain higher peak performance.
At fixed compute, dense annotation accelerates both WAM mid-training and VLA post-training — even after charging caption-generation compute against the budget. Adding language to existing demonstrations is a practical and compute-efficient lever for robot policy learning.